
400-123-4567
13988999988
公司地址:广东省广州市天河区88号
联系方式:400-123-4567
公司传真:+86-123-4567
手机:13988999988
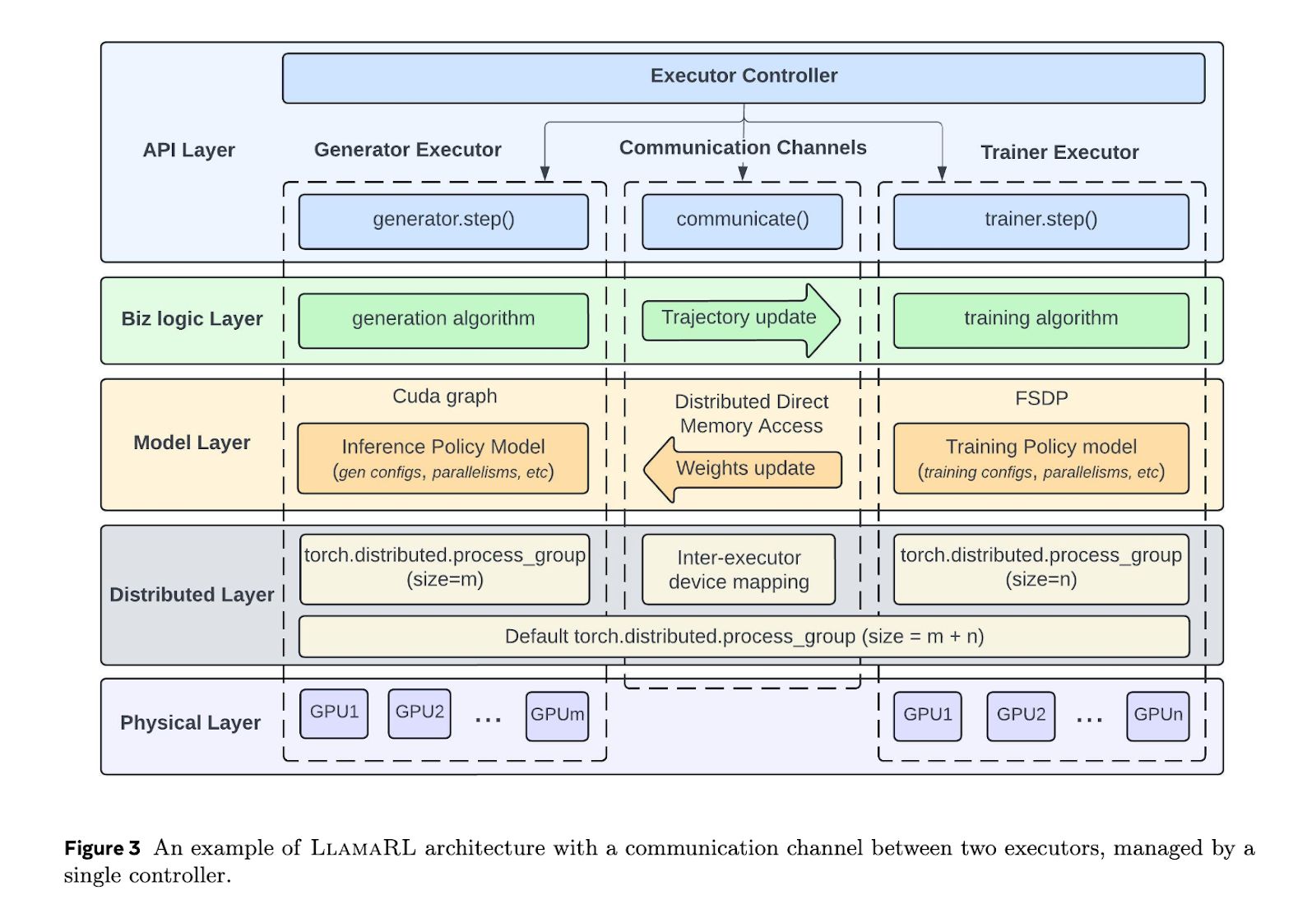 该新闻的6月11日,技术媒体Marktechpost昨天(6月10日)发表了一篇博客文章,报道Meta推出了Llamarl大纲,该大纲采用了完全非分布式设计的分发。在405b参数模型中,Llamarl Shorte的加固时间从635.8秒增加到59.5秒,并提高速度10.7倍。主页注意:加固(RL)研究根据反馈调整输出,以使模型与用户的需求更加一致。尽管模型准确性和适应规则的要求将继续增加,但加强培训后阶段的重要性变得越来越突出,并且持续的模型性能优化已成为许多高级大型语言模型系统的主要因素。对大语言模型进行研究的最大障碍是资源需求。该培训涉及大量计算和多收入协调,例如技术,奖励得分手等。AMARL Framework使用Pytorch生成一个完全不合格的系统,简化了协调并支持模块化自定义。通过与独立高管一致的生成,培训和奖励模型的处理,Llamarl大大降低了等待时间并提高效率。 Llamarl使用共享的直接访问记忆(DDMA)和NVIDIA NVLINK技术,在短短2秒内实现405B减肥参数重量的重量。在实际试验中,Llamarl在8.90秒,20.67秒和8B,70B和405B模型中缩短了训练时间,速度增加了10.7倍。 Math和GSM8K基准测试表明它们的性能稳定,甚至略有改进。 Llamarl有效地解决了记忆限制和GPU效率问题,为训练大型语言模型打开了一条衡量的路径。
该新闻的6月11日,技术媒体Marktechpost昨天(6月10日)发表了一篇博客文章,报道Meta推出了Llamarl大纲,该大纲采用了完全非分布式设计的分发。在405b参数模型中,Llamarl Shorte的加固时间从635.8秒增加到59.5秒,并提高速度10.7倍。主页注意:加固(RL)研究根据反馈调整输出,以使模型与用户的需求更加一致。尽管模型准确性和适应规则的要求将继续增加,但加强培训后阶段的重要性变得越来越突出,并且持续的模型性能优化已成为许多高级大型语言模型系统的主要因素。对大语言模型进行研究的最大障碍是资源需求。该培训涉及大量计算和多收入协调,例如技术,奖励得分手等。AMARL Framework使用Pytorch生成一个完全不合格的系统,简化了协调并支持模块化自定义。通过与独立高管一致的生成,培训和奖励模型的处理,Llamarl大大降低了等待时间并提高效率。 Llamarl使用共享的直接访问记忆(DDMA)和NVIDIA NVLINK技术,在短短2秒内实现405B减肥参数重量的重量。在实际试验中,Llamarl在8.90秒,20.67秒和8B,70B和405B模型中缩短了训练时间,速度增加了10.7倍。 Math和GSM8K基准测试表明它们的性能稳定,甚至略有改进。 Llamarl有效地解决了记忆限制和GPU效率问题,为训练大型语言模型打开了一条衡量的路径。